Hello Arrow
Demo
![]()
Some “Big” Data
Apache Arrow Specification
In-memory columnar format: a standardized, language-agnostic specification for representing structured, table-like data sets in-memory.
![]()
A Multi-Language Toolbox
Accelerated Data Interchange
Accelerated In-Memory Processing
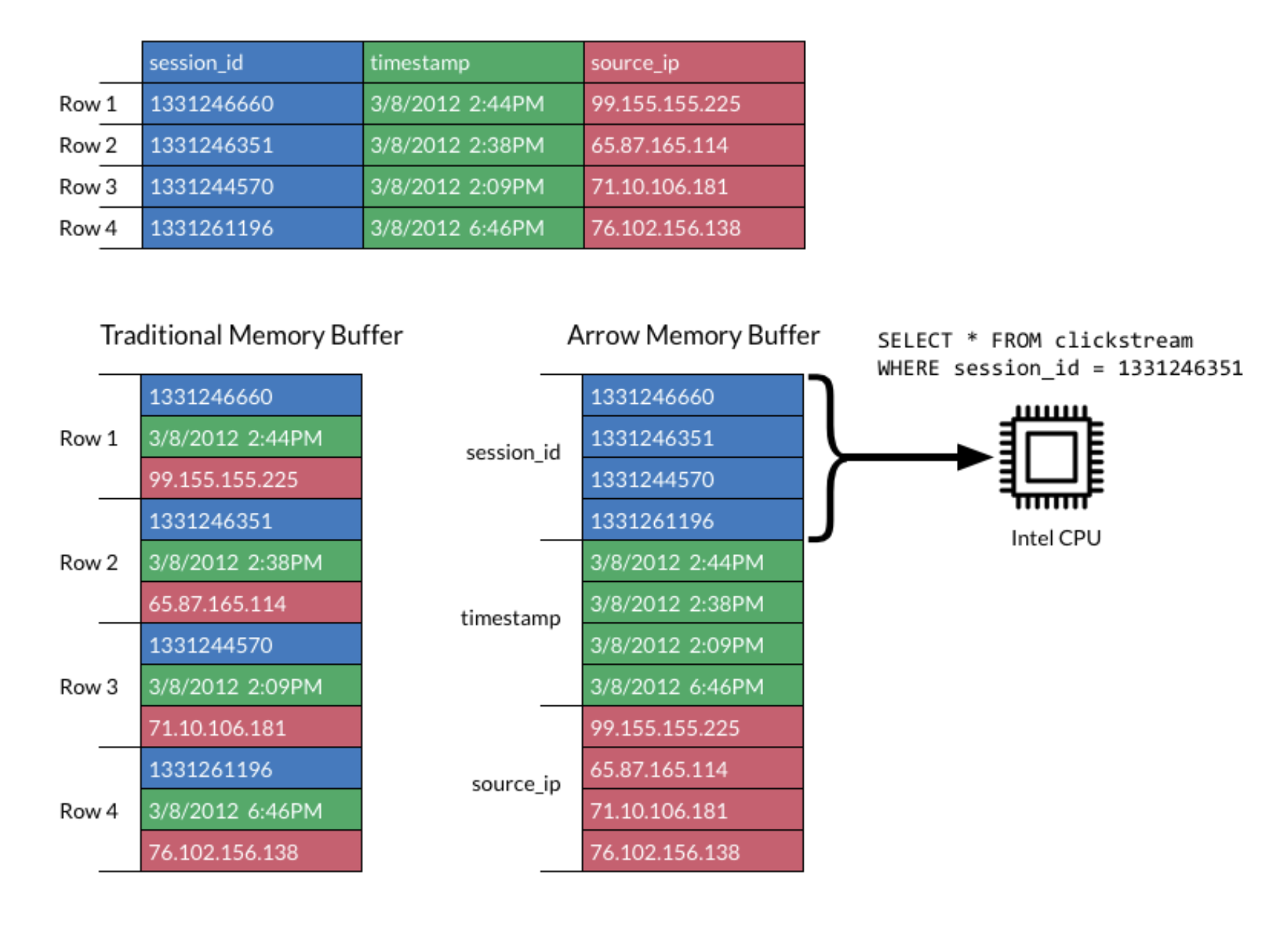
Arrow’s Columnar Format is Fast
arrow 📦
![]()
arrow 📦
Today
- Module 1: Larger-than-memory data manipulation with Arrow—Part I
- Module 2: Data engineering with Arrow
- Module 3: In-memory workflows in R with Arrow
- Module 4: Larger-than-memory data manipulation with Arrow—Part II
![]()